Wer sein Netzwerk mit Checkmk oder anderen Monitoring-Tools überwachen will, muss zunächst die Hosts und deren Dienste konfigurieren. Wenn diese Informationen bereits in einer CMDB (Configuration Management Database) vorliegen, kann man sich die manuelle Doppelarbeit sparen und mit dem CMDB Syncer die Daten automatisiert übernehmen. Das klappt inzwischen sogar in beiden Richtungen. Bastian Kuhn, der Autor des Open-Source-Werkzeugs, berichtet hier über die Entwicklung des Tools, seine Erfahrungen und welche Funktionen es sonst noch so bereitstellt.
In diesem Beitrag möchte ich die Geschichte des CMDB Syncers erzählen. Anfangs habe ich dieses Open-Source-Automation-Tool dazu programmiert, einfache Datenbanken oder CSV-Dateien mit Checkmk stetig abzugleichen. Aber die Geschichte beginnt noch zuvor.
Daten-Import in Checkmk
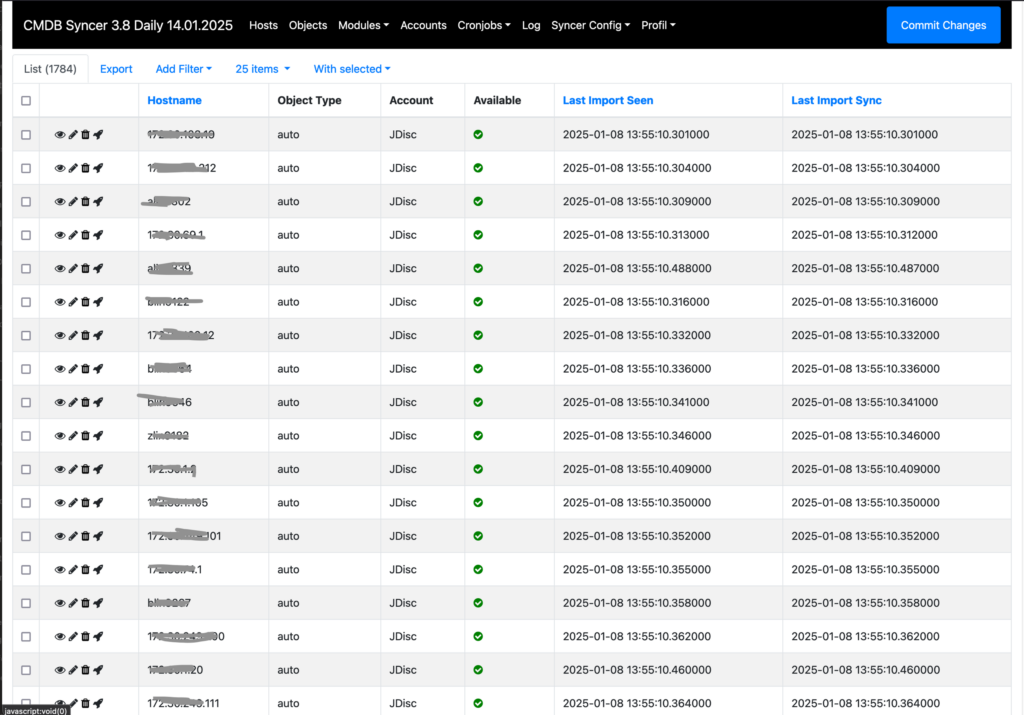
Zu den Anfangszeiten von Checkmk, als ich dieses Monitoring-Tool bei den ersten Firmen eingeführt hatte, spielte sich alles noch in Konfigurationsdateien ab. Hier konnte man bereits mit sogenannten Python-Hacks arbeiten, um große Mengen an Objekten, genannt Hosts, schnell und einmalig nach Checkmk zu importieren. Erst später, als die Konfiguration unter dem Namen WATO in eine Weboberfläche verlagert wurde, stand auch eine einfache API-Schnittstelle zur Verfügung, die sogenannte Web-API. Diese war jedoch noch weit von dem entfernt, was bei Checkmk 2.0 mit der ersten Version der Rest-API eingeführt wurde. Immerhin konnte man in der Checkmk-Oberfläche von Anfang an CSV-Dateien importieren. Darüber lässt sich schnell ein einmaliger Import von Daten umsetzen.
In den darauffolgenden Jahren habe ich öfter Unterstützung geleistet, Scripte zu entwickeln, die bei einem dynamischen Befüllen von Checkmk unterstützten. Kaum eine Umgebung ist nämlich so statisch, dass es mit einem einmaligen Import getan ist. Diese Scripte funktionierten meist auch ausgezeichnet. Mit jedem Checkmk-Update brauchten diese zwar etwas Pflege, aber die Aufgabe wurde immer zufriedenstellend gelöst. Dummerweise musste man für jede neue Umgebung ein neues Script schreiben.
Wie alles begann
Die Motivation zu CMDB Syncer entstand in einem Projekt bei einem großen Telefonanbieter. Dieser war damals noch auf Checkmk 1.5, wollte jedoch auf Checkmk 1.6 updaten. Eine talentierte Praktikantin hatte dort bereits eine Lösung entwickelt, die über Nacht, in mehreren Stunden, die Umgebung mit damals 7000 Hosts mit einer Datenbank abgleichen konnte. Der Umzug auf Version 1.6 fand statt, die Praktikantin verließ die Abteilung und alles war gut. Nur war jetzt niemand mehr da, der das Script betreute. Leider ein häufiges Problem bei Eigenlösungen, das mir auch bei anderen Kunden begegnete.
Hier war dann die Idee geboren, ein generisches Open-Source-Tool zu entwickeln, das die Automatisierung von Hosts ein für alle Mal löst. Das Programm sollte modular aufgebaut sein: Der Telefonanbieter plante damals, die cloudbasierte Automatisierungslösung ServiceNow einzuführen, außerdem sollte der CMDB Syncer weitere Datenquellen wie CSV-Dateien unterstützen. Die Verwendung von CSV-Dateien mag zwar veraltet klingen, aber selbst heute noch sind diese ein einfacher Weg, um das Problem fehlender Daten der hauseigenen CMDB transparent und hoffentlich nur vorübergehend zu lösen.
Da inzwischen Checkmk 2.0 mit der ersten Version der neuen Rest-API am Horizont erschien, war die alte Script-Lösung ohnehin angezählt. Dieses Problem hatten die Lösungen meiner anderen Kunden genauso.
Generische Lösung statt vieler Inseln
Nun hatte ich die Chance, anstelle verschiedener Insellösungen eine zentrale Lösung zu entwickeln, von der künftig alle profitieren konnten. CMDB Syncer 1.0 war rechtzeitig fertig für die Umstellung auf Checkmk 2.0. Bereits in dieser Version konnte der Syncer die Umgebung des Telefonanbieters, die damals noch mehrere Stunden dauerte, in 15 Minuten aktualisieren. Ein kleiner Blick nach heute: Die spätere Syncer-Version 3.5 braucht für selbige Installation weniger als zwei Minuten. Die mir größte bekannte Installation hat 135.000 Hosts, hier hängt die Geschwindigkeit natürlich auch stark von der Umgebung ab, auf welcher der Syncer betrieben wird. Aber wieder zurück zur Version 1.0. Den Syncer-Code habe ich auf GitHub hochgeladen. Version 1.0 war auch schon mit einer Weboberfläche ausgestattet, auf der man seine Hosts kontrollieren konnte.
Seither ist viel passiert. Während die erste Version nur den Anspruch hatte, das Anlegen von Hosts und deren Folder in Checkmk zu automatisieren, ist mit Version 2.0 des Syncers eine zentrale Regel-Engine und eine Plug-in-API hinzugekommen. Die Regel-Engine konnte man dann über die Weboberfläche schon voll konfigurieren.
Der regelbasierte Ansatz und seine Grenzen
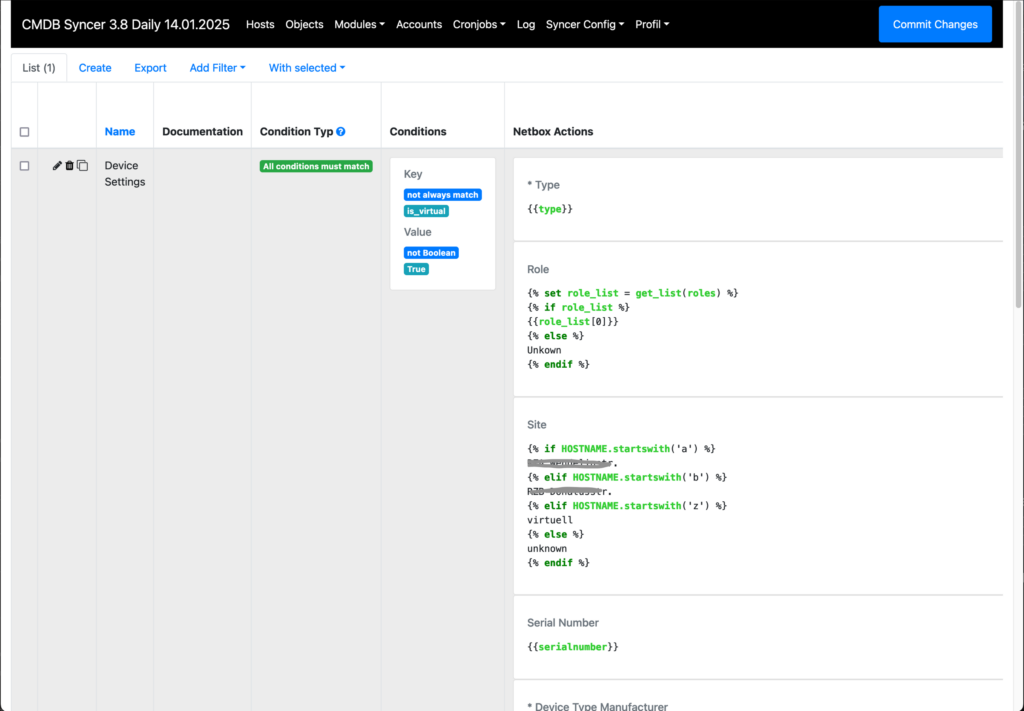
Wenn man Checkmk automatisieren will, wird schnell klar, dass mehr notwendig ist als nur Hosts anzulegen. Um die Konfiguration großer Mengen ähnlicher Hosts zu erleichtern, arbeitet Checkmk regelbasiert, nicht wie damals Nagios Template-basiert: Mit wenigen Regeln kann man sehr viel einstellen. Trotzdem kann es manchmal sehr repetitiv werden, weil sich nicht alles durch dynamische Regeln abbilden lässt.
Ein Beispiel: Hat man viele Abteilungen und will, dass jede Abteilung eine Mail bekommt, wenn mit einem ihrer Systeme ein Problem auftritt, sind mindestens zwei Regeln nötig:
- Eine Kontaktgruppe pro Abteilung
- Eine Assignment-Regel, die Hosts ihren passenden Kontaktgruppen zuordnet.
Bei zwanzig Abteilungen wären das 40 Regeln. Wird eine Abteilung umbenannt, muss man natürlich auch die Regeln nachziehen. Gibt es keine Hosts mehr, die zu einer Abteilung gehören, sollte man diese beiden Regeln auch wieder löschen. So lautet im Prinzip der erste Anwendungsfall, der über das Anlegen von Hosts hinausging.
Umfassender Abgleich
Durch weitere Anforderungen in Projekten entwickelten sich die Checkmk-Funktionen immer weiter. Inzwischen kann man mit dem Syncer fast alles in Checkmk automatisieren. Dazu zählen jegliche Regeln, BI-Aggregationen (Business Intelligence), DCD (Dynamic Configuration Daemon), User, Host-, Service- und Kontakt- und Tag-Gruppen, Hosttags, Labels oder auch den Password Store.
Da der Syncer viel über alle Hosts weiß, zum Beispiel auf welcher Checkmk-Site er später sein soll, bietet er sich auch als Ansible-Datenquelle an. Damit ließ sich die nächste Herausforderung lösen: knapp 5000 Hosts für die Checkmk-Bakery und TLS-Funktionen registrieren. So ist in der Lebenszeit der Syncer-Version 2, die Ansible-Schnittstelle inklusive entsprechender Playbooks für Linux und Windows hinzugekommen.
Mit Ansible einen Schritt weiter
Wer viele Hosts hat, verteilt diese meistens auch auf viele Checkmk-Sites. Viele Sites bedeutet aber auch viel Arbeit bei einem Versions- oder Patchlevel-Update. Diese Fleißaufgabe zu automatisieren lohnt sich vor allem, wenn man viele kleine Versionsschritte gehen will. Und da Automatisierung ohnehin die Domain des Syncers war, entwickelte ich die zweite Ansible-Funktion für den Syncer. In der Oberfläche konfiguriert man Sites, Server und Zielversionen. Auf der CLI führt man das fertige Ansible-Playbook aus, und die Sites werden bei Bedarf angelegt oder auf die Zielversion aktualisiert.
Neben neuen Funktionen ist die Pflege der API-Anbindung vor allem bei Checkmk ein Dauerthema. Nicht nur zwischen Checkmk 2.0, 2.1, 2.2 und 2.3 musste ich den Syncer aufgrund von API-Änderungen anpassen, selbst teilweise zwischen Patchleveln war dies notwendig. Die aktuelle Version 3 des Syncer unterstützt daher durch einen Konfigurations-Schalter für Checkmk bis 2.2 oder aber Checkmk 2.3. Ich bin gespannt, ob für Checkmk 2.4 ein weiterer Schalter notwendig wird.
Erstes großes Facelift
Als es beim Syncer dann an die Version 3 ging, gab es endlich das erste größere Facelift und Feature-Update. Von grauen Tabellen ging es zu modernen Designs, um Regeln, deren Bedingungen oder Outcomes darzustellen. Inzwischen läuft der Syncer auch öfter als Docker-Container, statt manuell installiert zu sein. Zur Version 3 gehört daher auch, dass der Anwender fast alles in der Weboberfläche erledigen kann. Nicht nur die Konfiguration, sondern auch das Ausführen von Syncer-Kommandos, Hochladen von CSV-Dateien oder das Prüfen von Logfiles.
Mit Version 3.5 ist etwas Externes dazugekommen: Checkmk-Checks, die den Syncer und seine Jobs überwachen können. Ist der Syncer nämlich mal konfiguriert, möchte man ihn ja nicht ständig selbst kontrollieren müssen, vor allem wenn man sowieso eine Netzmanagementlösung betreibt.
Rundum angebunden
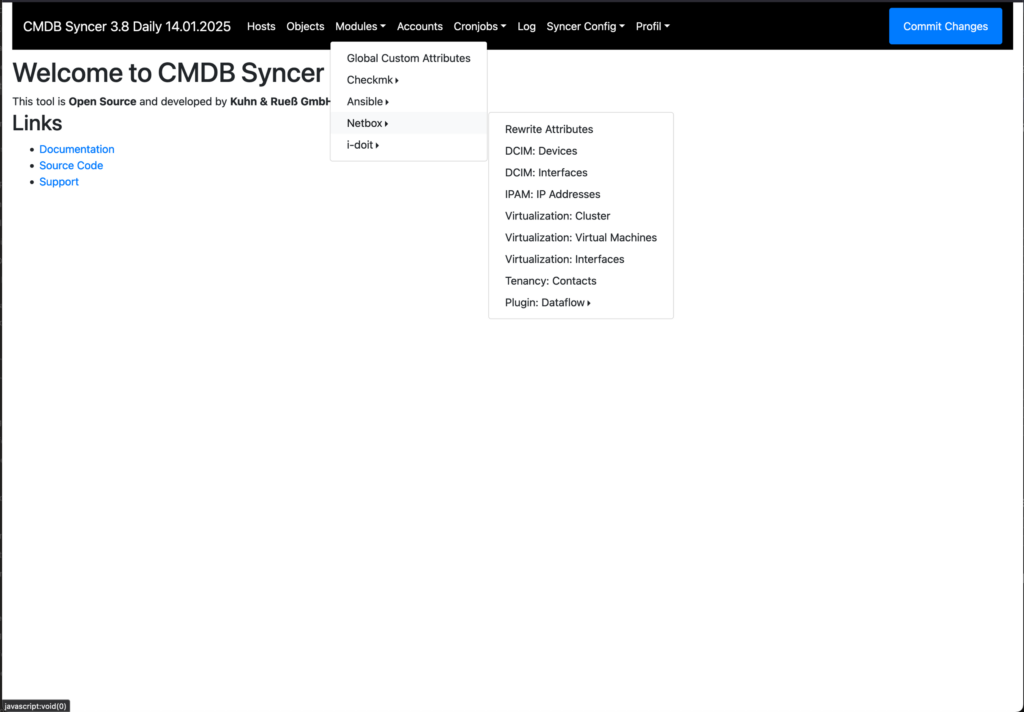
Bisher war alles, was ich erzählt habe, sehr Checkmk bezogen. Aber die Modularität des Systems hat eine große Stärke: Man kann in allen Richtungen abgleichen. Fast nebenher sind daher Anbindungen hinzugekommen, die weitere Systeme nicht nur abfragen, sondern auf Wunsch auch befüllen. Auch kann Checkmk nicht nur als Ziel, sondern auch als Datenquelle dienen, inklusive des HW/SW Inventory. Die gewonnenen Daten kann man an eine CMDB-Lösung wie I-Doit oder die Netzwerkdokumentationssoftware Netbox schicken. Oder andersherum, Netbox auslesen, Checkmk befüllen, aber Netbox doch wieder durch HW/SW Inventory Daten bereichern.
Ein paar weitere Anbindungen, die mit dabei sind, sind: CSV, JSON, MySQL, mssql, FreeDTS, Active Directory (LDAP), Jira, bmc-remedy oder JDisc. Durch die Plug-in-API kann man jede Quelle in kürzester Zeit einbinden.
Für ein weiteres Projekt in einer dynamischen Umgebung gibt es seit Version 3 im Syncer einen Rest-API-Endpunkt. Hierüber lassen sich Hosts und Attribute anlegen oder abfragen. Zum Hintergrund: Im besagten Projekt beginnt die Lebenszeit eines neuen Hosts nicht in einer CMDB (was ich jetzt nicht kommentieren will), sondern durch das Ausführen eines Ansible-Playbooks. Dieses Playbook schickt nun auch einen HTTP-Request zum Syncer, damit dieser den Host auch in Checkmk initial anlegt.
Spannende Zukunft
Ich bin gespannt, welche Anbindungen es in Zukunft noch geben wird. Es macht auf jeden Fall viel Spaß, diese zu entwickeln. Wer mehr über den Syncer erfahren will, kann dessen Dokumentation zurate ziehen oder direkt den Code auf Github lesen. Und natürlich kann er über die Linux Systems Consulting AG auch direkt Unterstützung erhalten.
Der Autor
Bastian Kuhn war der erste fest angestellte Consultant für Checkmk bei der damaligen Matthias Kettner GmbH, heute Checkmk GmbH. Als erfahrenes und geschätztes Mitglied der Community hat Bastian wichtige Funktionen entwickelt, darunter den hier vorgestellten CMDB-Syncer.